Заблаговременное знание того, когда актив выйдет из строя, позволяет избежать незапланированных простоев и поломки активов. Согласно публикации Deloitte, прогнозное техническое обслуживание (predictive maintenance) в среднем повышает производительность на 25%, сокращает количество аварий на 70%, увеличивает время безотказной работы оборудования на 10-20% при сокращении общих затрат на обслуживание на 5-10% и времени планирования обслуживания на 20-50%.
В условиях индустрии 4.0 техническое обслуживание означает гораздо больше, чем просто предотвращение простоев отдельных активов. Машины становятся все более взаимосвязанными по всей производственной цепочке. Один проблемный актив может остановить весь производственный процесс. В отличие от профилактического обслуживания, основанного на календарной периодичности или наработке, прогнозное обслуживание максимизирует время продуктивной работы активов, поскольку оно выполняется непосредственно перед отказом.
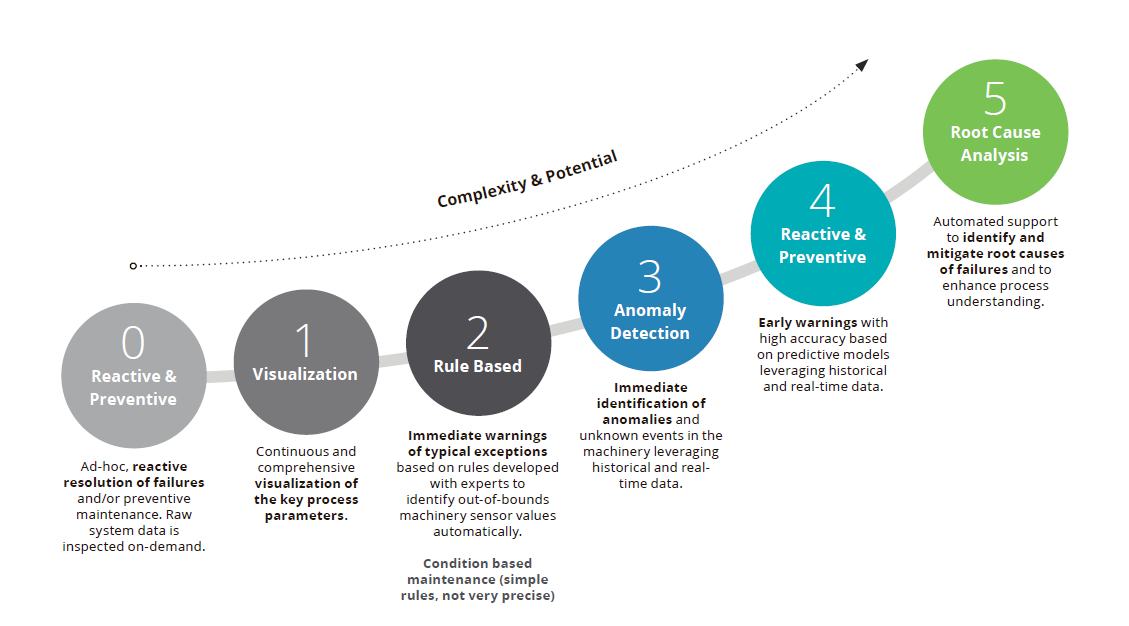
Deloitte разработала подход, позволяющий постепенно внедрять прогнозное техническое обслуживание в бизнес-процессы структурированным образом. Он основан на шести этапах движения к реализации прогнозного обслуживания. Поэтапный подход способствует снижению проектных рисков. Каждый очередной этап дает улучшенный эффект, что приводит к сокращению простоев и повышению производительности.
Начиная с этапа 0, основной целью является создание понимания процесса с помощью данных. Для шага 1 (визуализация) нужен постоянный поток данных датчиков в интегрированную платформу. Это позволяет реализовать видимость ключевых процессов, характеризующих техническое состояние оборудования. На этапе 2 (обслуживание, основанное на правилах) жизненно важна экспертная информация о процессе и его параметрах. На их основе мы можем вывести формализованные и простые, хотя и не очень точные, правила для принятия решений о выводе актива в ремонт или на техническое обслуживание при наличии выхода параметров за определенные рамки. Применение таких правил уже может предотвратить большую часть отказов.
На этапе 3 (обнаружение аномалий) требуется достаточное количество накопленных данных датчиков с необходимой частотой измерений на единицу времени и датчик. Эти данные позволяют определить норму для любого процесса, а также отклонения от нормы. Выявление аномалий и неизвестных событий в оборудовании повлечет за собой оповещение операторов, которые должны будут решить, произошел ли фактический отказ.
На следующем этапе (реагирование и предупреждение) нужно значительное количество подробных документированных данных о развитии отказов. Применяя расширенную аналитику, можно обнаруживать признаки зарождающихся отказов немедленно и надежно. На пятом этапе (анализ коренных причин) необходимы записи как об успешных, так и неудачных действиях, чтобы устранять коренные причины отказов.
Однако, не каждой организации нужно внедрять predictive maintenance. Чтобы понять свои потребности и готовность к проекту в этой области необходимо оценить критически важные требования и степень зрелости системы технического обслуживания. Для этого следует ответить на ряд вопросов:
- Насколько надежными должны быть наши активы?
- Каковы наши целевые показатели доступности?
- Какова текущая частота отказов наших машин?
- Насколько высоки наши текущие затраты на техническое обслуживание?
- Есть ли у нас нужные запасные части в нужном месте в нужное время?
- Как мы определяем, когда пришло время заменить актив, а не поддерживать его в рабочем состоянии?
- Какие данные, которые у нас уже есть, используются неэффективно?
- Определили ли мы критически важные активы в нашей производственной системе?
- Есть ли какие-то важные активы, которые выиграют от программы прогнозного обслуживания?
- Обладаем ли мы необходимыми технологическими знаниями для разработки программы прогнозного обслуживания?
- Есть ли у меня в штате опытные специалисты по аналитике?